Keine Normalverteilung: Bootstrapping als Alternative
Eigentlich geht es im Statistiker-Blog um aktuelle Statistiken. Immer mal wieder gab es aber auch Themen zu statistischen Themen, beispielsweise zur Wahrscheinlichkeitsrechnung oder Excel. Zu meinem großen Erstaunen habe ich festgestellt, dass gerade die Beiträge mit Nutzerwert sehr gerne gelesen werden. Deshalb kommt heute wieder ein eher anwendungsorientiert Beitrag.
Statistiken auswerten: Voraussetzungen prüfen!
Einer der Hauptgründe aus dem Studenten und junge Forscher in der Statistik Hilfe benötigen, ist die Verletzung der grundlegenden Annahmen von parametrischen Verfahren. Wie kann ich meine postulierten Kausalzusammenhänge überprüfen und Statistiken auswerten, wenn die Beschaffenheit der Daten keine parametrischen Verfahren erlaubt? Statistik-Anfänger suchen in solchen Fällen oft professionelle Statistik Hilfe für Studenten, jedoch machen Verfahren wie Bootstrapping Statistik um einiges flexibler.
Zur Analyse von metrischen Variablen eignet sich das klassische lineare Modell. Wichtige Spezialfälle hiervon sind die linearen Regression und die Varianzanalyse. Voraussetzung dafür ist, dass die Residuen normalverteilt sind. Wenn diese Annahme erfüllt ist, folgen auch die Y-Werte einer Normalverteilung und man kann einen so genannten parametrischen Test, also einen Test, der auf einer Verteilungsannahme basiert, verwenden. In realen Projekten ist die Normalverteilung jedoch leider selten.
In diesen Fällen kann man versuchen die Daten durch eine Transformation an die Normalverteilung anzunähern. Eine häufige Methode ist hier das Logarithmieren. Falls dies jedoch nicht funktioniert, muss man sich bei einfachen Modelle mit nur einer erklärenden Variablen auf nichtparametrische Test-Alternativen beschränken, da von diesen keine Verteilungsannahme mehr getroffen wird (für den parametrischen t-Test ist das z.B. der Mann-Whitney-U Test). Nachteil dieser verteilungsfreien Tests ist meist die geringere Genauigkeit durch das Fehlen von Informationen. Weiterhin fehlt es für komplexere Modelle vollkommen an solchen nicht-parametrischen Alternativen. Abhilfe kann hier das Bootstrapping schaffen, dass die Anwendung von parametrischen Verfahren durch das künstliche Erzeugen einer Normalverteilung erlaubt.
Warum ist die Normalverteilung Voraussetzung?
Will man das Modell nur zur Erstellung einer Prognose verwenden, ist diese Annahme gar nicht erforderlich. Egal wie die Residuen verteilt sind, die Koeffizienten-Schätzer sind nicht verzerrt. Erst wenn es um die Interpretation von Konfidenzintervallen und Hypothesentests geht, wird die Normalverteilung zur Pflicht.
Die Grundlage hierfür wird im Folgenden anhand einer multiplen linearen Regression erklärt.
Unser Modell sieht folgendermaßen aus:
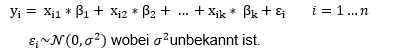
Die Schätzfunktionen ![]() folgen in diesem Fall, wenn also die Residuen normalverteilt sind, ebenfalls einer Normalverteilung. Mit dieser Information können wir das Konfidenzintervall von ßi konstruieren. Auch die Verteilung der Wald-Test-Statistik unter der Null-Hypothese ist uns dann bekannt. Dadurch können wir Hypothesen-Tests durchführen indem wir den Wert der Test-Statistik mit den Quantilen einer t-Verteilung vergleichen.
folgen in diesem Fall, wenn also die Residuen normalverteilt sind, ebenfalls einer Normalverteilung. Mit dieser Information können wir das Konfidenzintervall von ßi konstruieren. Auch die Verteilung der Wald-Test-Statistik unter der Null-Hypothese ist uns dann bekannt. Dadurch können wir Hypothesen-Tests durchführen indem wir den Wert der Test-Statistik mit den Quantilen einer t-Verteilung vergleichen.
Falls die Residuen aber nicht normalverteilt sind, dann wissen wir auch nichts über die Verteilung der Schätzfunktionen und der Wald-Test-Statistik. Das bedeutet, dass das betrachtete Konfidenzintervall verzerrt ist und es keinen Sinn macht den Wert der Test-Statistik mit den Quantilen der t-Verteilung zu vergleichen. Wenn man diese Problematik ignoriert, dann kann es zu schwerwiegenden Verletzungen des Konfidenzniveaus kommen. Das Konfidenzniveau wird nämlich nur dann eingehalten, wenn die Stichprobe wirklich aus einer Normalverteilung stammt.
Diese Gefahr droht jedes Mal, wenn wir Konfidenzintervalle konstruieren oder Hypothesen testen wollen. Wenn die Residuen nicht normalverteilt sind, dann stimmt auch die für die Test-Statistik angenommene Verteilung nicht und deswegen ist der Test wertlos. Die Lösung für dieses Problem ist, anstatt eine bestimmte Verteilung zu unterstellen, die Stichprobe selbst als Verteilungsmodell zu nehmen. Genau das ist der Ansatz den Bootstrapping verwendet.
Bootstrapping Statistik: Was ist das?
Um Ihnen bei dem Umgang mit der Statistik Hilfe zu bieten, wollten wir erstmal auf die Grundlagen des Bootstrapping eingehen. „Sich an den eigenen Stiefelriemen aus dem Sumpf ziehen“- das schaffte der Held der amerikanischen Variante der Münchhausen-Geschichte. Und genau das ist auch das Prinzip des statistischen Verfahrens das daher seinen Namen hat: Bootstrapping.
Die Idee ist einfach. Anstatt anzunehmen, dass die interessierende Prüfgröße einer bestimmten Verteilung folgt, unterstellen wir jetzt, dass dessen Verteilungsfunktion gleich ihrer empirischen Verteilungsfunktion ist.
Diese empirische Verteilungsfunktion der Test-Statistik erhalten wir, indem wir sie wiederholt berechnen. Dazu generieren wir uns aus dem Originalsample viele weitere, so genannte, Bootstrap-Stichproben der gleichen Größe. Das geschieht indem man Werte aus der originalen Stichprobe zieht, notiert und dann wieder zurücklegt. Dadurch können die Bootstrap-Stichproben Werte der originalen Stichprobe auch mehrfach enthalten. Aus jeder der so neu generierten Bootstrap-Stichprobe wird nun mit den üblichen Methoden der Wert der Test-Statistik bestimmt. So erhält man dann dessen empirische Verteilung, woraus sich dann Konfidenzintervalle und Hypothesen-Tests konstruieren lassen, die auch bei einer Verletzung der Normalität der Residuen gültig sind. Bootstrapping ermöglicht also vorher nicht anwendbare Methoden die es uns erlauben, dass wir unsere Statistiken auswerten.
Und nun ein Bootstrapping Beispiel
Das Bootstrapping schauen wir uns nun am Beispiel der multiplen linearen Regression an. Dieses Mal nehmen wir aber an, dass die Residuen keiner Normalverteilung folgen. Unser Ziel ist die empirische Verteilung der Koeffizienten-Schätzer zu bestimmen.
- Zuerst schätzen wir die Koeffizienten auf Basis der originalen Stichprobe
- Dann berechnen wir für jede Beobachtung den angepassten Wert und das Residuum
- Diese Stichprobe der Residuen wollen wir nun durch Bootrapping replizieren. Also ziehe wir mit Zurücklegen, um viele weitere Sekundärstichproben der Residuen der gleichen Größe zu erhalten
- Jede dieser Sekundärstichprobe modifizieren wir nun so, dass wir der Reihe nach die angepassten Werte addieren. Damit machen wir also aus den Bootstrap-Stichproben der Residuen, solche der Y-Werte
- Mit diesen Sekundärstichproben der Y Werten und den fixen X werten berechne wir nun wiederholt die interessierende Prüfgröße – den Koeffizienten Schätzer.
Aus der resultierenden Stichprobe der Test-Statistiken lässt sich dessen empirische Verteilung bestimmen.
Zwar wird bei diesem Verfahren keine Annahme über die Verteilung der Residuen getroffen, es wird aber, durch das eben beschriebene Verfahren implizit angenommen, dass diese identisch verteilt sind.
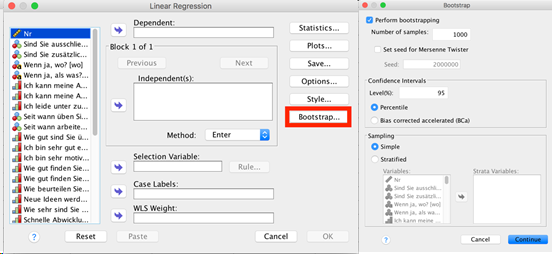
Hat man nun die Stichprobe der wiederholten Test-Statistik vorliegen, kann man dessen Mittelwert und die Standardabweichung schätzen. Dafür sind 100-200 Bootstrap-Stichproben ausreichend. Für die Konstruktion von Konfidenzintervallen und Hypothesentests sollten jedoch mindestens 1000-2000 replizierte Stichproben verwendet werden. Die Bestimmung der statistischen Signifikanz findet beim Bootstrapping über die Konfidenzintervalle statt. Hierbei unterscheidet man zwischen dem Perzentil Konfidenzintervall, dem Bias-Corrected Konfidenzintervall und dem Bias-Corrected adjusted Konfidenzintervall. Liegt die Null nicht in dem jeweiligen Konfidenzintervall, so kann von einem signifikanten Konfidenzen ausgegangen werden.
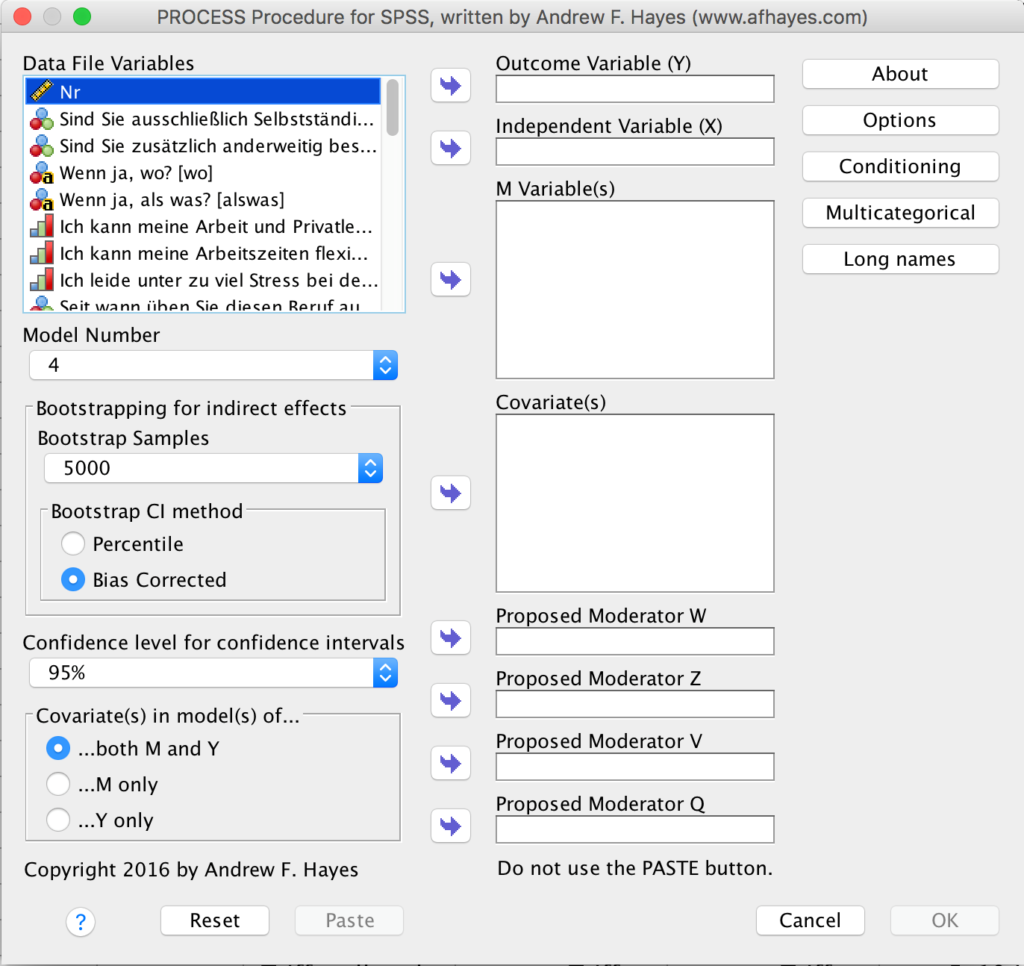
Das Bootstrapping ist somit eine hervorragende Lösung, wenn die Annahme der Normalverteilung nicht eingehalten wird, man sich aber nicht auf nicht-parametrische Verfahren beschränken möchte. Dieses Verfahren ist natürlich auch in den gängigen Statistik-Software-Programmen enthalten und wird für einige Verfahren explizit empfohlen, wie zum Beispiel für die Mediationsanalyse mit dem PROCESS Macro für SPSS und SAS.
Guten Tag,
ihre Erläuterungen haben mir bei meiner Masterarbeit sehr geholfen. Haben Sie vielleicht noch eine Quelle, in der man dies weiter nachlesen kann?
Vielen Dank für den guten Einblick in das Thema. Ich suche nun schon seit längerem Literatur dazu, welcher Umfang für das Bootstrapping gewählt werden sollte – 5000, 10.000, 20.000,…? Wovon hängt die Entscheidung ab? Bei mir geht es speziell um die Mediationsanalyse mit PROCESS. Für eine Antwort oder einen literatur-Tipp wäre ich sehr dankbar. Viele Grüße